Demystifying Apache Kafka: A Comprehensive Guide to Real-Time Data Streaming
In this article I am going to discuss about Apache Kafka as well as we will try to understand what is apache kafka, what problem apache kafka solved, apache kafka architecture and why apache kafka so much popular in the tech industry.
What is Apache Kafka?
Apache kafka is an open source distributed event streaming platform, we can call it message broker service. Apache kafka use thousands of companies to handle their application almost 80% of tech company are using apache kafka. Apache kafka are commonly used in micro services architecture. In micro services architecture one service can send message to another service thought apache kafka which is called producer and receiver service receive message through apache kafka it’s called consumer.
What problem solved by apache Kafka?
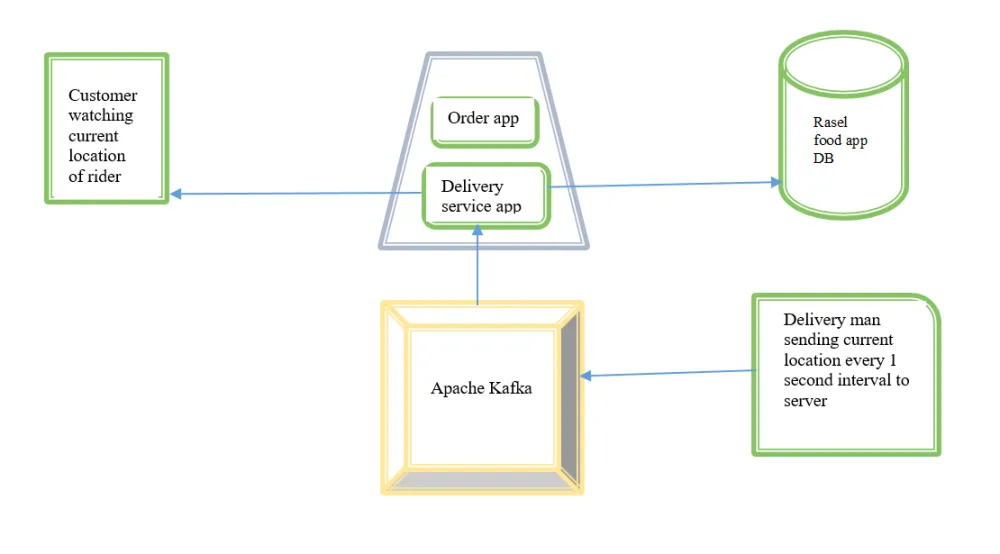
Let’s discuss problem statement. Assume that I have food delivery app called Rasel Food Delevery app. In this food delivery app has 4 components like customer, food app server, food app database, and delivery man or rider location. See bellow diagram.

Assume customer want to buy a burger he selects a burger and make order from rasel food delivery app, after order he can see current location of his food and how much time to take etc.
On the other hand, rider taking food and going to customer current location. In this situation rider sending his current location to rasel food app server every 1 second interval, server taking location data save to database and sending to customer in this way customer watching current location of rider.
In the above food delivery app did you find any problem? Yes, there was a big problem. Suppose in my food app 1000 rider working for food delivery. Each rider sends his current location after 1 second interval, that’s means in 1 second 1000 database operation happened. Now try to increase number of rider like 10000, 20000 the system will be crashed because of database throughput called OPS (operation per second). Throughput means how many data we can insert per second in a database, and we all know that database has low throughput. Because of low throughput we cannot insert data as many as we want in one second This problem has been solved by apache kafka. Apache kafka has high throughput.
Using apache kafka we can take billions of request and make bulk insert to database in this case database is completely save zone. Now you can think apache kafka can solve this issue why we use database? We have to remember that kafka has high throughput and low storage capacity on the other hand database has high storage capacity and low throughput. We can query data from database but we cannot use query inside kafka. So we have to use both kafka and databases. Bellow given diagram problem has been solved by apache kafka.

Apache Kafka architecture:
1. Producer: producer is send message to kafka.
2. Consumer: consumer receive message from kafka here remember that we can have multiple consumers.
3. Topic: topic is one kind or category suppose in chat app we can create multiple chat room. Each room name is different we can call each chat room is topic.
4. Partition: We can create partition inside topic. Each topic can have multiple partition we can compare partition same like HDD partition
5. Consumer Group: using kafka we can send message to group of consumer.

Here producer send message to specific topic inside apache kafka, and kafka send message to consumers. Assume that we have multiple partition inside specific topic and multiple consumer what happened? If we have multiple partition and 1 consumer this single consumer can consume message from all partition. If we have 2 partition and 2 consumers first partition message going to first consumer and second partition message going to second consumer. But imagine we have 2 partition and 3 consumers in this case one consumer sitting in idle (third consumer will not get any message).
Without multiple partition we can send message but problem is when we send lot of message to topic without partition in this case message overflow happened. We use partition here for data separation same like database splitting or HDD partitioning.
Important note: in this apache kafka has 2 important rules:
1. One consumer can access multiple partition
2. But one partition can access only one consumer.
For solving this problem apache kafka has another component called consumer groups

If we look above diagram Partision1 send message to consumer 1 and 2 under the consumer group 1 and partition 1 and 2 both sending message to consumer 1 under the consumer groups 2.
Why apache kafka is popular:
If we look at other event streaming platform like redis and rabbitmq, redis is follow pub/sub pattern and rabbitmq follow queue pattern. But in this apache kafka follow both pattern pub/sub and queue.